

Epoch AI recently released a new set of AI benchmarks, and the GPT-5 model’s performance is among the best. In this independent study, industry leaders Grok 4, Claude Opus, and several OpenAI systems were tested. The purpose of this study is to determine model accuracy in reasoning, coding, and math tasks.
GPT-5 maintained its strength in reasoning and coding while demonstrating a distinct advantage in challenging math tasks. Furthermore, the GPT-5 mini, its smaller sibling, demonstrated efficiency without significant accuracy trade-offs, achieving results comparable to the flagship.
How GPT-5 Performance Shapes AI Benchmark Leadership
Epoch AI evaluated models using the Pass@1 metric, which captures accurate first-attempt responses. The results demonstrate how well GPT-5 performs in software engineering and advanced knowledge tests, as well as mathematical reasoning.
Why GPT-5 Performance Dominates the Toughest Math Challenges?
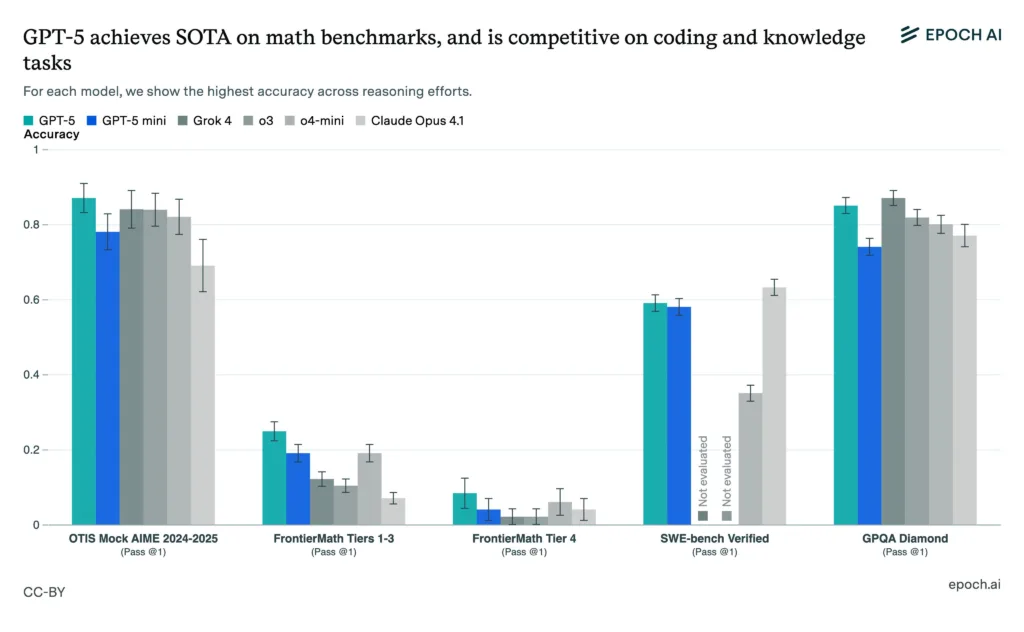
GPT-5 achieved roughly 88% on the OTIS Mock AIME 2024–2025, with GPT-5 mini following closely behind. Claude Opus and o4-mini scored lower, while Grok 4 and o3 came next. Additionally, GPT-5 ranked first in FrontierMath Tiers 1–3 according to AI benchmarks, although scores decreased because of difficulty. Although Tier 4 was difficult for everyone, GPT-5 held a slight advantage.
AI Benchmarks Confirm Strongest Models for Developers
The SWE-bench Verified test highlighted GPT-5’s coding strength. GPT-5 and GPT-5 mini both had model accuracy scores of roughly 59%, with little variation. However, o3 and o4-mini scored significantly lower, and Grok 4 and Claude Opus were not tested.
GPT-5 Performance Competes Closely in Complex Reasoning
In the GPQA Diamond benchmark, Grok 4 scored about 86% and GPT-5 85%, while other models fell slightly short. The small disparity suggests intense competition in fields that demand a high level of reasoning.
AI Benchmarks Point to New Era of Competition
GPT-5 performs well in reasoning-intensive domains, especially math, where it exhibits efficient training and design methods. The GPT-5 mini’s high ranking across a number of AI benchmarks demonstrates that smaller systems can achieve higher model accuracy. Thus, this is beneficial for resource-constrained deployments. Businesses will have to weigh efficiency and adaptability against raw performance as a result of the heightened level of competition.
Will GPT-5 Performance Keep Its Top Position?
Epoch AI’s results confirm GPT-5 performance as a leader in advanced math and coding. The GPT-5 mini and other smaller versions demonstrate that well-designed models can achieve near-flagship accuracy.
As a result, there will be more options for deployment. Additionally, as competition heats up, improvements will probably happen more quickly in the upcoming years. This will raise doubts about any one model’s ability to hold its lead for an extended period.





