

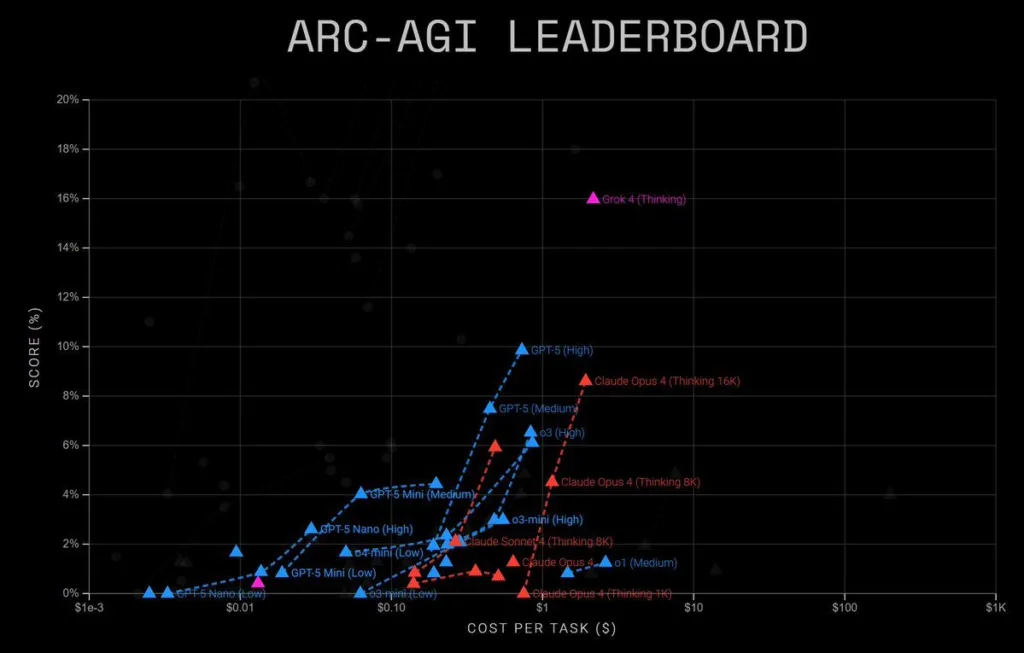
Grok 4 has surpassed OpenAI’s GPT-5 to take the lead on the ARC-AGI leaderboard in the latest AI benchmark results. This benchmark provides a clear picture of model efficiency by comparing the cost per task to advanced reasoning ability. Grok’s latest version, created by Elon Musk’s xAI, has improved its position in the competitive AI market. Thus, a new performance record is being set. Furthermore, the accuracy and operational value of the difference over GPT-5 are clear.
Grok 4 Stays Far Ahead on the ARC-AGI Leaderboard
The ARC-AGI leaderboard compares operational costs and performance ratings. GPT-5 scores high at 10%, while Grok 4 scores about 16%. The horizontal axis displays the cost per task on a logarithmic scale, and the vertical axis shows the score percentage. Thus, this makes cost-effective, high-performing models stand out.
Grok 4 surpasses the efficiency of comparable systems without the cost of many top-end models. The task cost less than one dollar. Additionally, Grok has become a leader in large-scale reasoning tasks due to its accuracy and affordability.
On the other hand, the performance of OpenAI’s GPT-5 series increases from Nano to High versions. Although it is still competitive, the top-tier GPT-5 High does not match Grok’s performance. Furthermore, lower-tier GPT-5 versions severely reduce costs at the expense of accuracy, which limits their advantage in challenging reasoning tasks.
Shaping the Future of AI Benchmark Performance
Claude Opus 4 from Anthropic is also trailing in the latest AI benchmark rankings. Grok’s top score is still a lot higher than the 16K Thinking model’s. Therefore, that variant only receives about a 9% score. In applications where cost is a concern, certain Claude configurations are costlier than GPT-5 but offer comparable or worse accuracy.
A wider change in the industry is reflected in the results. AI systems are increasingly being assessed on their ability to strike a balance between cognitive ability and economic efficiency. Furthermore, ARC-AGI-2 and other benchmarks show how cost-to-performance ratios will affect the adoption of AI in research and enterprise settings.
Is the ARC-AGI Leaderboard Pointing to a New AI Era?
The latest ARC-AGI leaderboard update indicates multiple competitive victories. Grok’s impressive performance establishes a new benchmark for fusing cutting-edge logic with affordable prices. Additionally, surpassing Claude Opus 4 and GPT-5 shows that high intelligence scores can be attained without incurring excessive operating costs.
Grok 4 may gain a sustainable edge in the upcoming stage of AI development if xAI can sustain or enhance these outcomes. Furthermore, Grok’s performance challenges conventional wisdom regarding the scaling of costs with intelligence, demonstrating that this balance is achievable.
Every leaderboard release in the ongoing race toward AGI will garner a lot of attention. Moreover, the competition is becoming more intense, and future updates may see another shift in the rankings.





